This is the prepared text of a talk I gave at DockerConEU 2015.

‘Trust yourself. You know more than you think.’ If I have to distil this talk into one phrase it will be that. My experience in initiating and prosecuting change within an organisation has only hardened my view that it’s you – the engineer who’s been shipping code for years, the technical leader who’s been fighting the good fight in meeting after meeting – it’s you that knows what needs to be done, and often that involves doing things that may feel, or even be wrong. And I hope that by the end you’ll feel emboldened to trust yourself that bit more and enable Docker for your own organisation in your own way.


My name is Ian Miell and I’m honoured to be talking here today, given that so many great people submitted talks I’d have liked to hear.
So why should you listen to me? From a Docker perspective I’ve done all of the usual community things:
– written one of the three million docker ecosystem tools (sorry)
– had so many builds on dockerhub they had to ask me to stop (sorry)
– write a Docker and DevOps blog
– spoken at meetups
– published a video on Docker aimed at web developers
– published a book on Docker in Practice
I worked for 14 years for the leading supplier of online sports betting and casino software and pounced on Docker as a solution for many of problems I faced as Head of DevOps (whatever that means) and latterly when I was put in charge of IT Infrastructure as well. Using this and other experience, I then moved on somewhere else where a large chunk of my responsibility is to be a reference point for Docker.
It’s the practical angle I want to talk about today. About how getting Docker done in a living, breathing organisation meant breaking some rules, and how it worked out for me. I hope it’s useful to some of you, and if not, I hope it’s at least interesting.

First I need to set the scene of why I decided to go all-in on Docker.

In September 2013 I read in Wired magazine about a new technology called Docker.
The timing couldn’t have been more perfect. I was a DevOps Manager with no budget for DevOps, in a company that couldn’t get a useful VM infrastructure going. We were a software company with 25 customers, and of those about 6 were big players. They competed with each other to throw changes out as fast as possible and were willing to accept technical debt, even wear it as a badge of commitment to delivery. I knew this because I lived daily with the consequences. I was responsible for managing outages.
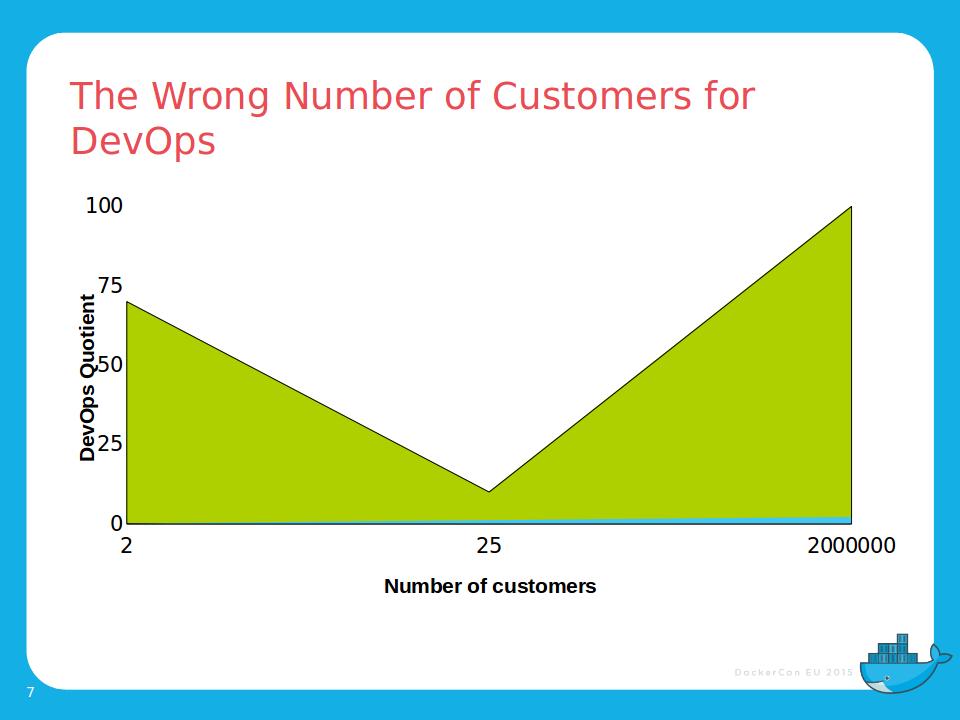
I liked to argue that we had exactly the wrong number of customers to avoid technical debt – if we had two customers of similar size we could do things consistently between them, if we had 200,000 we could do what we wanted, and they would vote with their feet. On top this we were a time and materials company, and which customer would want to pay for testing that other customers get the benefit from?
As it was we had a few big players with big pockets who wanted to differentiate themselves from their rivals by pushing forking changes out faster. Not a great environment for productization, and there were subtle and significant differences between customer systems.

As Live Problem Manager and DevOps Head my biggest frustration was an inability to create realistic customer-specific environments to reproduce problems. Environments were a rare commodity, hand-crafted by old hands like me based on folklore, wiki pages full of bash commands hurriedly noted, and old-fashioned grit. New features always took priority and no customer wanted to pay to sort out technical debt, but were happy to pay to shout at me.

I’d long bemoaned this and wondered what could be done about it. The standard answers: VMs + Chef/Puppet/Ansible were not yielding results, since no-one wanted to tackle this 15-year old software stack and no-one had the time. As an aside, one of the commonest objections to my advocacy of Docker was: ‘you can do all that with VMs’. Which is true, but it’s far less convenient, iterations are slower, and in my experience it’s less stable and more painful to use. Tellingly, our technical presales engineer – who had to manage multiple environments in various states – went back to maintaining shell scripts for his laptop’s envs because VMs ‘were not worth the hassle’. In any case, despite the talk, no-one had managed to demonstrate this working. As I’ll discuss later, the time and resource-savings that containers bring change the paradigm of development.
After reading the article I checked the project out, started using it, and on Monday went into work with a proof of concept

which led to my first choice:

At this point I could have gone to my management and argued the case for this new technology, and waited for a decision and a budget. I chose not to. Instead I sent an email out on the Monday asking whether anyone else had heard of it and whether anyone wanted to work on a way of solving some of our problems. I’ll talk about what happened next in a moment, but at this point I want to talk about failure.
It was failure that drove me down this path, because I’d been here before. In 2006 I and a few others advocated the use of Erlang to solve some specific engineering challenges we were going to have in the coming years to do with scalability and real-time data. We went to the CTO and asked for his support. After many months a relatively insignificant and unrelated toy project was given to someone else in the company apparently uninterested in learning a new technology, and we watched as the results withered on the vine. I still don’t know whether that was the right outcome or not, but I’d seen enough not to let the fate of my vision depend on something I had so little influence over.
As an aside, I think the parallels between Erlang and the whole ‘Data centre as an Computer’ movement, of which Docker is a part, are under-explored. In case you don’t know, Erlang was an engineering solution to the problems of fault tolerance in data centres for telcos that has a message-passing architecture.

You can’t get much more microservices than services built from millions of co-routines that take up only a few dozen bytes of memory by default, and this standard Erlang diagram is one that will look familiar to anyone who’s used Kubernetes. Anyone interested in what happens next with microservices will do well to look at the history of Erlang.
But back to the point. After sending out my email I had a few responses and a small group of people interested in taking things further. This had a number of beneficial consequences in the following months:
– the team was motivated, and the quality of engineers involved was high
– those that didn’t deliver anything found they had no voice and dropped out
– conversely, those that did deliver got a say and felt empowered to contribute more
– it was fun! solving long-standing problems one by one and pulling together was incredibly satisfying
– time was allocated naturally to where we felt it was important – there was no bureaucracy, no deliverables, no project plans, no business case
By focussing on building solutions rather than seeking support elsewhere a lot of time and energy was saved. A lot, but not all. I had to pull in a lot of favours to get resources and access to things outside the normal processes. A lot of chatter ensued in the organisation about what we were doing, and the supposed conflict between what we were working on and the more strategic solutions being posited as solutions by others.
Much of this chatter centred around our solutions not being ‘industry standard’, which leads me to my next choice:

When I saw Docker I thought ‘great!’ – I can run multiple reproducible environments cheaply, save state usefully, all without much hassle and outlay. So the natural and immediate plan was to simply shove everything into a container and allow everyone to consume it as a reference.

I went onto mailing lists to ask about how to achieve this, and got responses like ‘I wouldn’t start from here – you should be using microservices, that’s what Docker is for’.
Fortunately I had the confidence to decide against doing this, mainly because the task was too great. Converting a 15-year old hub-and-spoke architecture with millions of lines of codes and hundreds of apps was a project I didn’t want to take on in my spare time, and would have doomed my efforts to complete failure. I think the area of legacy is a fascinating one for Docker, and it’s going to have to deal with it. Based on experiences at these and other organisations, I’ve come to believe that the approach to Docker for legacy apps should be in three stages:

– Monolithic build, the speed of which enables
– A DevOps workflow, which naturally leads to
– A break-up into microservices
The point is that real projects, real budgets (0 in my case) cannot afford to do everything properly, and even if they do, they risk running into the sand and losing momentum. An evolutionary approach is required.
Given that I had a monolith to contain my next choice was how to build it. Again, I need to set the scene.

Since environments were created by hand by experienced engineers in whatever inconsistent environments supplied by our customers, there was a lack of configuration management experience where I worked. Nonetheless, I figured I should try and do the standard thing, and spent one of my precious weekend days trying to learn chef by watching some introductory videos. A couple of hours later time was running out and I was no nearer. At this point – and out of frustration – I whipped up a solution which I knew would work for me using tools I already knew – Python, bash and (p)expect.
I didn’t believe this was the ideal, but I’d built what I needed and I had complete control over it and I knew that our project could deliver something useful quickly. When I showed what I’d done to people at work, the response typically was: ‘you should be using industry standard tools for this’, to which my response was: ‘agreed, here’s the shell scripts, here’s how I’ve done it, please replicate what I’ve done with whichever tool you like and we’ll move to it’. No-one did this.
This approach proved to be very useful for the project for a number of reasons:
One, I’d designed it to be easy to hack on. As an engineer, all you needed to do to contribute was cut and paste code that amounted to shell commands and re-run on your laptop. As our work got taken up through the organisation, contributions were easily made by others.
Two, the tool did exactly what we needed to achieve our goal: no more, and no less. If it didn’t, we built it. This was fun, and empowering. I learned a hell of a lot about config management tooling challenges, which has helped me a great deal as I’ve moved on and picked up other ‘real’ configuration management tools as part of my work. [As an aside, I did a similar thing with CI tools like Jenkins – I implemented a minimal CI tool in bash called ‘cheapci’, available on github which also helped me understand the problems of CI.]
Three, it allowed us to defer the decision about what configuration management tool to use. Since I’d designed it to organise a series of shell scripts and run them in a defined order, one of the outputs was a list of commands that could be fed into any tool you liked, even run in by hand.
So, as with monoliths, I’m not sure ‘not invented here’ deserves such a bad rep. If your aim is to deliver and control your solution and you have the skills, building your own tool can be the right choice, at least for getting your project done. And if you want to get Docker working in your organisation, getting to useful is your first priority. The tool eventually became known as ShutIt (ie not Chef, not Puppet: ShutIt), and after 4 months of legal discussion became open-sourced, and I still maintain it as one of those three million ecosystem tools. To be clear, I don’t suggest you use ShutIt (though I welcome contributions), I’m just using it as an example of how not invented here can be the right choice on the ground.
At this point I want to dwell on one of the points I just made in order to bring me onto

As I just mentioned, one of my design goals for ShutIt was that it should not get in the way of engineers that wanted to contribute to our endeavour. I didn’t want people to have to learn both Docker and another technology to contribute.
This was part of a broader plan to get people on board with what we were doing as far as possible, to reduce the barriers to entry, and to increase cross-fertilization between different parts of the company.

One of the patterns of failure I’d seen in attempts at technical change was that it was guarded and defended by a group of elite engineers, with little attempt made to persuade others – ie those that would eventually have to build on and maintain their efforts – to understand what was going on. A former colleague of mine pointed out that he’d been forced to use Maven with little support and that this caused him great resentment.
So from the very beginning I made sure I talked openly about what we were up to, both inside and outside the company.
One thing I was absolutely determined to make sure of following my experience with Erlang was to ensure that I took responsibility for knowledge sharing.
First I tried doing lectures in a room, which went OK, but I had a lucky accident which led me down a different path. I couldn’t get a room for a session, so decided to do it over Google hangout instead. This made the whole process way more efficient. People would remain at their desks as I introduced the material, and then they worked through the examples, speaking up when they got stuck. It allowed people to work at their own pace, be interrupted and feel like they had me as a helper as they learned themselves. I could even get on with other work while they worked through it. The PR effect was massive, as people felt part of the change, and that encouraged a number of great ideas came out of it and made people want to smooth our path. I couldn’t recommend this more. And I’m in good company:

I came across this quote coincidentally last week and couldn’t agree with it more.
The other thing I did was put myself out there at meetups and talk openly about what we were up to and how we were doing it. What I found interesting was a pattern of thought emerged which held people back from advocating change. Consistently, people would tell me that their organisation was dysfunctional

…but that company X, or even all other companies seemed to have it sorted out:

I haven’t seen this place. I’ve seen some places do some things better than others, but usually these are the things that those businesses exist to do; it’s what they’re optimized for.
So much for the decisions. How did we get Docker taken up and what did it do for us?
One of our number worked in a team of forty engineers, and took up the challenge of getting his colleagues to use it.
There was significant resistance at first. Believe it or not people were happy maintaining environments by hand. The critical insight we had was that while someone is on a project they don’t want to change, but when they came to starting the next project, the benefits of the ‘dev env in a can’ were obvious.
Then, as more people started to use it, a network effect was created, and once about 8 were on it, the others soon followed.

There are many I could mention, but I want to talk about three benefits here that Docker faciliated. As more and more engineers embraced it, these benefits became mutually reinforcing in a virtuous circle.

By having a repeatable daily build of a development environment, friction between engineers and teams was significantly reduced.
Before Docker, environments were unique, so discussions about the software often devolved down to discussions of the archaeology of that environment. Since we now had a reproducible way to get to the same starting state, reproduction of state became simpler.
I ran the 3rd line support team, and with Docker we could instantly get an environment up and running to recreate problems seen on live without begging favours from environment owners. In an early win for Docker I managed to reproduce a database engine crash from a single SQL command moments after we saw it happen on live. No need to find an environment that people were using, check it was OK to crash – this was contained on my laptop and I didn’t even have to wait for an OS to boot up.
Interactions with test teams were made far simpler also. The daily build of the dev environment had some automated endpoint testing added to it, and the test team were notified by email, with the logs attached. This reduced the friction of interaction between testers and developers greatly, as there was no debate or negotiation about the environments being discussed.
Speed of delivery was also facilitated. Since fixes to the environment setup were shared across the team, there was a reduction in duplicated effort, and benefits fed into the automated build. Testing these changes was much quicker thanks to the layered filesystem, which our build tool leveraged to allow quick testing before a full phoenix build.
To show I eat my own dogfood, I wrote a website a few years ago in my spare time to track mortgage rates; it’s called themortgagemeter.com. I rebuild this site from scratch daily (video here). Doing that has had a number of very useful consequences. I can quickly make changes and run very simple tests against this static system, then throw it away if it doesn’t work. Very little overhead. It also acts as a canary – I’ve caught some interesting problems very quickly that I otherwise wouldn’t had I rebuilt on demand.

Quality was also improved by being able to iterate faster and earlier in the cycle than before. A vivid example of this was with DB upgrades. Formerly, as we’d only had a few environments that were expensive to re-provision, DB upgrades were a haphazard and costly affair that took place on infrastructure hosted centrally.

Now DB upgrades could be iterated in very tight cycles on the dev laptop, reducing the cost of failure and improving the quality by the time the customer saw it.

Our CI process was also changed in two significant ways.
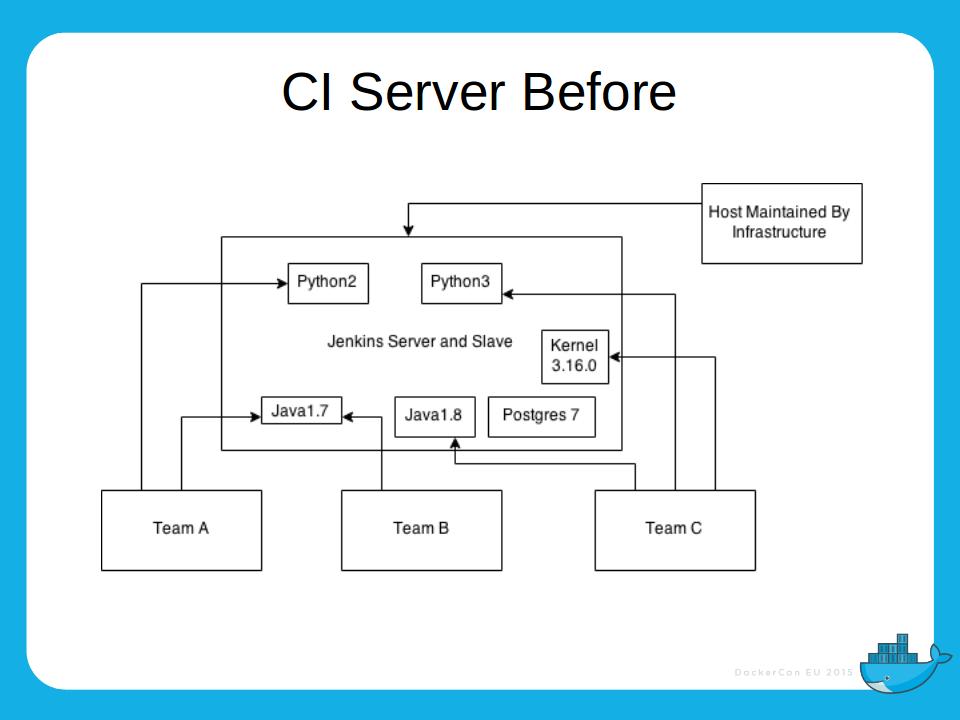
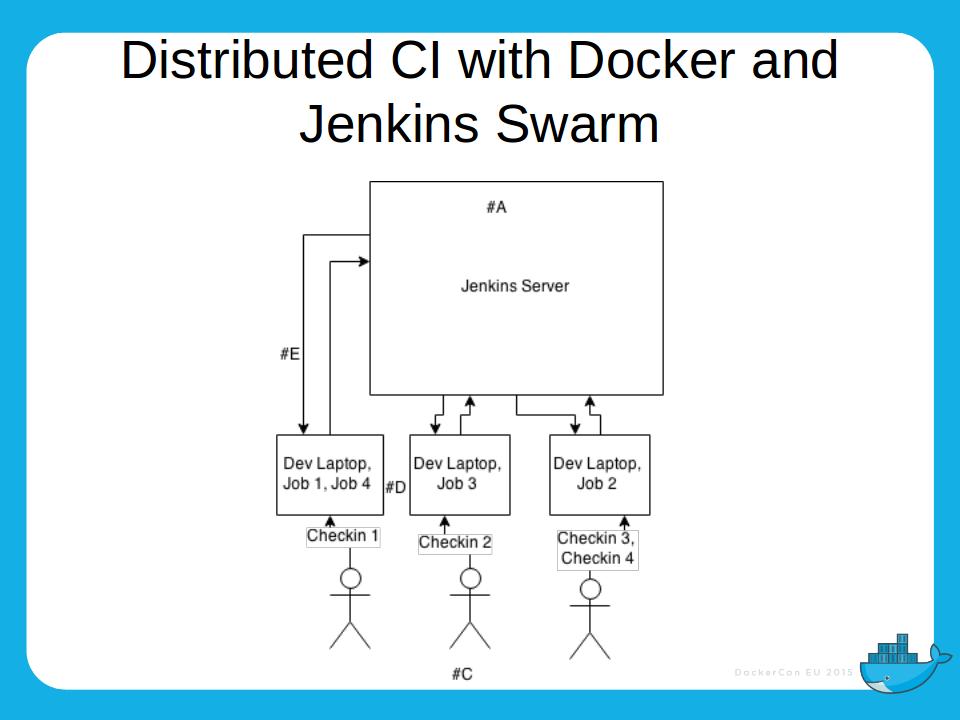
We had a monolithic model of CI where we had an enormous Jenkins server shared across all teams, and on which changes could not easily be made – if you want a new version of python, for example, that created all sorts of headaches for the central IT team, who found it hard to maintain stability while accommodating these demands. Docker threw all that out:

Teams could now take ownership of their own environments and take responsibility for stability themselves by producing their own images and containing dependencies to their own isolated environments.
What we did went beyond that, as we used the Jenkins Swarm plugin (not to be confused with the Docker product) to allow the developers’ own laptops to run CI. As one of my colleagues put it ‘why is it so hard for me to provision a VM when I have a Corei5 laptop on my desk that’s mostly idle?‘. So developers would submit their hardware to the Jenkins server as slaves, and Docker images were run on the hardware. This had the interesting property of allowing the compute to scale with the team – the more people that were in work committing changes, the more compute was available to use.
Once we’d done all this and got Docker embedded we looked for ways to measure the return on investment. We had plenty of anecdotal evidence by this back and positive feedback from both engineers and customers
There was one small but vivid example of the savings made. There was an escrow process that we had to go through with some customers that involved demonstrating to an auditor that in the event of a disaster the customer could reconstruct the website without us. Traditionally, this had taken a fair number of days to work through, and a good amount of negotiation with the auditor to get them to accept. In addition, it was un-repeatable – it took n days each time. With Docker and the tooling we’d built, we not only completed the task in one-fifth of the time, but also the auditor (who had never heard of Docker) was satisfied after watching one run-through that reconstruction was replicable, and the developers on that team got their environment into a container.

These sorts of anecdotes were all very well, but we wanted to put real numbers on it. To this end we performed a survey of engineers that were actively using it, which boiled down to a simple question: how much time is this saving you a month? To cut to the chase, the rough figure was around 4 days for those users that actively embraced it. Interestingly, we found that engineers were reluctant to admit time was saved, as they felt that somehow this made them feel like they’d been inefficient pre-docker.
In any case, if we took a 4-day/ month figure and apply that across the 600 engineers we came up with a figure of about 130 person years saved per year, which amounted to a lot of money, as you can imagine. And bear in mind that this was before we get to improvements in customer perception, which is a less tangible, but no less important benefit, or even efficiencies in hardware usage, which were significant.
Conclusion
These decisions are not advice! All of these decisions were made in the context I had worked in for over a decade. If you already have working CM tools, maybe you should use those! If your C-level have a good history of funding and delivering promising projects, maybe skunkworks is needlessly hamstringing yourself. As I said at the beginning, you’re the one in your current situation and in the best place to figure out what needs to be done.
Thanks for listening.

The experience discussed here informed the writing of this book: Get 39% off with the code 39miell


2 thoughts on “DockerConEU 2015 Talk – You Know More Than You Think”